Это задача — классика алгоритмов. В каждом языке программирования есть свои особенности.
Для паскаля, к примеру, строка — это массив символов, потому можно сказать, что задача решена уже по определению. Для PHP один из вариантов решения задачи можно найти в документации — откройте описание функции preg_split().
|
1 2 3 4 5 |
<?php $str = 'string'; $chars = preg_split('//', $str, -1, PREG_SPLIT_NO_EMPTY); print_r($chars); ?> |
Этот пример не работает для UTF-8 символов, но это легко исправить:
|
1 |
$chars = preg_split('//u', $str, NULL, PREG_SPLIT_NO_EMPTY); |
Изящное и быстродействующее решение, несмотря на использование функции, работающей с регулярным выражением. Назовем его Алгоритм 1.
Я сравнивал быстродействие вот с такой конструкцией, использующей функции работы с много-байтовыми строками (пусть это будет Алгоритм 2):
|
1 2 3 4 |
$len = mb_strlen($str); $chars = array(); for ($k = 0; $k < $len; $k++) $chars[] = mb_substr($str, $k, 1); |
Для коротких строк (у меня в тестах до 40-45 символов) алгоритм 2 выигрывает немного в быстродействии. Потом пальму первенства выхватывает алгоритм 1.
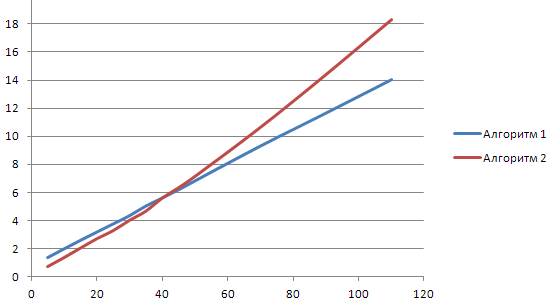
По оси OХ — длина строки (в символах), по оси OY — время вычисления (в секундах).
Спасибо!
Кратко и понятно.
Пример для UTF-8 вызывает ошибку 500, не знаю как это объяснить, там нет пробелов при просмотре скрытых символов, если их добавить, то работает.