Речь идет о № 839 с leetcode.
Формулируется проблема таким образом — дан массив строк, которые отличаются (или не отличаются) друг от друга перестановкой букв. Подобными считаются 2 строки, отличающиеся друг от друга только одной перестановкой или равные друг другу.
При этом если строка 1 подобна строке 2, а строка 2 подобна строке 3, то все три должны попасть в одну группу подобия. Хотя строка 1 может не быть подобна строке 3.
Результатом является кол-во групп подобия.
Во-первых, как определить подобность?
Если мы сравним две строки, то результат одной перестановки приведет к тому, что у нас появится несовпадение по двух буквам. Т.е. подобными будут строки с 2 отличиями или равные.
Во-вторых, что можно оптимизировать?
По сути, нам нужно сравнить все строки друг с другом, чтобы определить их принадлежность к группам. Т.е. это вложенный цикл попарных сравнений, которых нам не избежать. Нам не требуется сравнивать строки, только если они уже принадлежат к одной и той же группе. Например если мы сравнивали строки 1 и 2, а потом 1 и 3, и оказалось что они подобны, то строку 2 и 3 уже сравнивать не надо.
Нам понадобится для каждой строки где то отмечать информацию: к какой группе она принадлежит — у меня это будут одномерный массив grp.
Может выясниться, что подобными являются строки из уже известных групп. В таком случае нужно будет объединить две группы.
Собираю все мысли воедино, и вот что вышло (TypeScript):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
function numSimilarGroups(strs: string[]): number { // кол-во строк, длина одной строки: const len = strs.length, slen = strs[0].length; // массив принадлежности к группам, вначале у всех // проставим группу 0 const grp: number[] = new Array(len).fill(0); // следующий свободный индекс группы и число групп let nxtGrp = 1, countGrp = 0; // начнем попарное сравнение for (let i = 0; i < len - 1; i ++) { for (let j = i + 1; j < len; j ++) { // оптимизация: строки уже в одной группе, пропускаем if (grp[j] > 0 && grp[j] == grp[i]) continue; // подсчет числа отличий строк let count = 0 for (let k = 0; k < slen; k++) { if (strs[i][k] !== strs[j][k]) { count++; // оптимизация: // если отличий больше 2х, то можно // прервать подсчет, т.к. значения count > 2 // нам не интересны if (count > 2) break; } } // проверка подобия if (count == 2 || count == 0) { // оба элемента ни в одной из групп: // создать новую группу if (grp[i] == 0 && grp[j] == 0) { grp[j] = grp[i] = nxtGrp ++ countGrp ++; // оба элемента в одной из групп: // объединить группы } else if (grp[i] > 0 && grp[j] > 0) { const obsoleteGrp = grp[j]; grp.forEach((elm, ind) => { if (elm == obsoleteGrp) grp[ind] = grp[i]; }) countGrp --; // один из элементов уже в "банде": // присоединяем элемент к группе } else if (grp[i] > 0) { grp[j] = grp[i] } else { grp[i] = grp[j] } } } } // может оказаться, что какие то элементы не // попали в какую либо группу, тогда они образуют // свою уникальную группу. grp.forEach(elm => {if (elm == 0) countGrp++}); return countGrp }; |
Задача отмечена как hard, и наверное, можно придумать как её решать «сложным» способом, например динамическим алгоритмом или рекурсивно в том или ином виде, но я что то не придумал такого варианта. А моё решение, наверное, больше подходит для средней сложности задач.
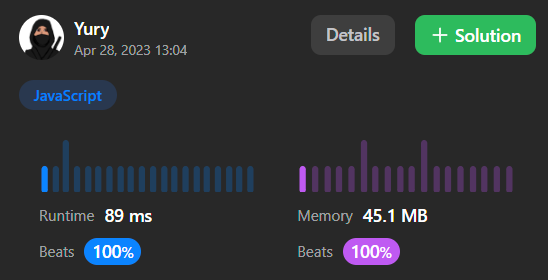
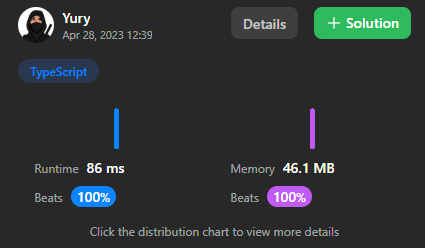
Тем не менее, задача решена, и судя по бенчмаркам leetcode — весьма хорошо. К сожалению, на TS у меня нет конкурентов, чтобы оценить.
Потому я решил переписать её на JS, и сравнить результаты там. Как видите, всё отлично и тут.