На работе не сильно много задач, решил немного поучиться. Удалось отхватить курс «Аналитик данных» в Фин Универе с поддержкой гос-ва. В качестве первого модуля изучаем пакет аналитики — loginom.
Здесь я приведу разбор одной из задач, которую нам дали в качестве доп. задания.
Задача была взята с отборочного тура Loginom Хакатон 2019. Нужно создать компонент «Случайная категория».
Входные данные:
На входе у нас две таблицы. Первая содержит список из N объектов с уникальными идентификаторами ID. Вторая таблица задаёт закон распределения дискретной случайной величины. Это случайное значение будем называть категорией (оно строкового типа).
Результат:
Список из N объектов с уникальным ID и присвоенная случайная категория из таблицы 2 с учетом закона распределения, заданного таблицей 2.
Дополнительно:
Дополнительно даётся набор данных hakaton_sales.lgd, в котором представлена историческая информация по продажам. Набор состоит из следующих полей:
- Дата — дата продажи;
- ID клиента — уникальный ID клиента;
- Код товара — ID приобретенного товара;
- Кол-во — кол-во приобретенного товара;
- Сумма — сумма, потраченная клиентом.
Решение:
Из исходного набора данных подготовим требуемые для задачи массивы:
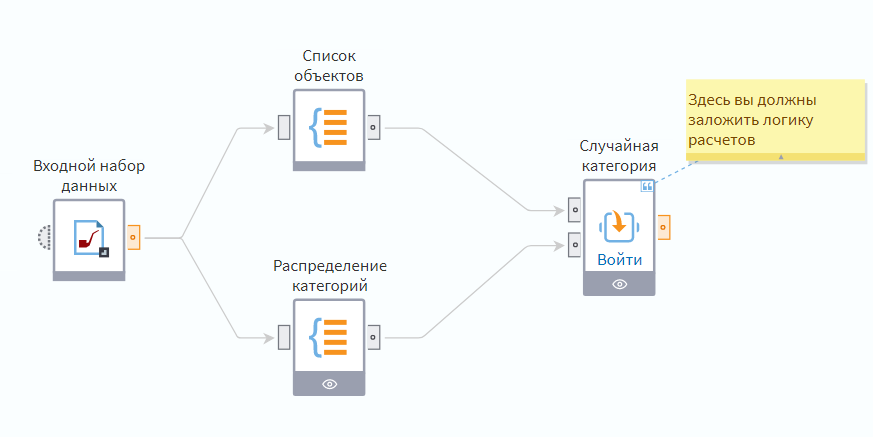
Группировка ‘список объектов’ — это выборка уникальных ID клиентов, а ‘распределение категорий’ — это группировка кода товара по количеству приобретенного товара.

Фактически, мы получаем абсолютное распределение товара в продажах. Т.е. если «Товара А» было продано больше, чем «Товара Б» в два раза, то ожидается, что данная категория товара будет встречаться в два раза чаще при использовании нашего компонента ‘случайная категория’.
Идея реализации
С помощью калькулятора мы легко можем добавить поле со случайным значением в таблицу 1. После этого, нужно как то присоединить таблицу 2, пользуясь ‘весами’ категорий. Если использовать компоненты из секции программирования — js или python, то нужные операции не сложно выполнить. Как пример, вот решение с использованием компонента js.
Реализация на JS
Подмодель ‘Случайная категория’ содержит всего три блока. Я выполняю подготовительные операции, чтобы не делать их в JS.
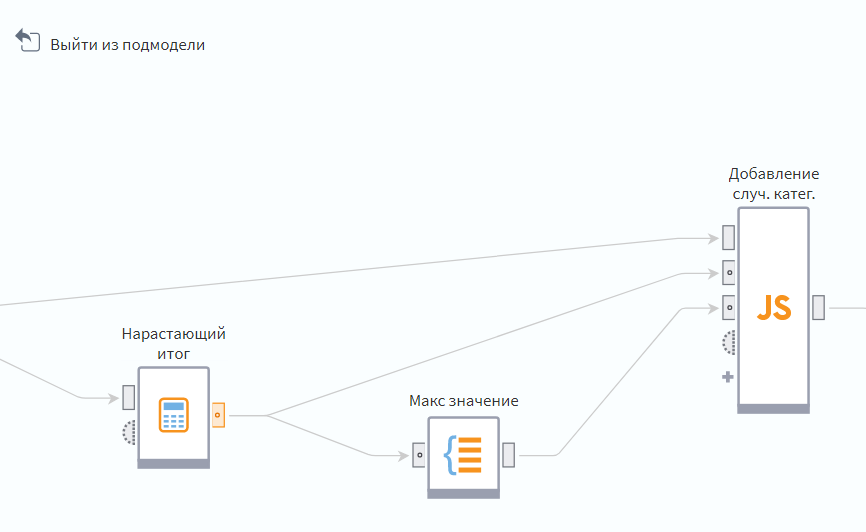
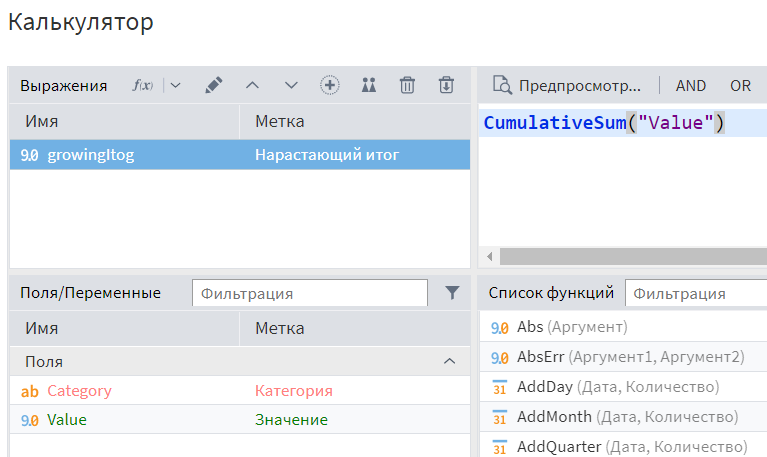
‘Нарастающий итог’ позволяет нам преобразовать ‘вес’ категории в шкалу категорий:
После этого мы вычисляем максимальное значение, чтобы опять же не делать это в скрипте и, далее, выполняем обработку входного массива в JS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import { InputTable, InputTables, InputVariables, OutputTable, DataType, DataKind, UsageType } from "builtIn/Data"; var maxValue = InputTables[2].Get(0, 0); // Чтение значений из входной таблицы for (let i = 0, с = InputTables[0].RowCount; i < с; i++) { OutputTable.Append(); OutputTable.Set(0, InputTables[0].Get(i, 0)); let CurrentRandomLevel = Math.random() * maxValue; // поиск категории по сформированной шкале let j = 0; while (CurrentRandomLevel > InputTables[1].Get(j, 1)) j++; OutputTable.Set(1, InputTables[1].Get(j, "Category")); } |
Случайное значение CurrentRandomLevel сопоставляется со шкалой, таким образом выбирается случайная категория и формируется выходной массив.
Реализация без JS
Преподаватель решил, что использование программирования — это оверинжениринг, так же он запретил использовать компонент ‘Цикл’.
Основная проблема — это сопоставить шкалу и таблицу 1. Мне удалось придумать, как это сделать используя компонент ‘Квантование’.
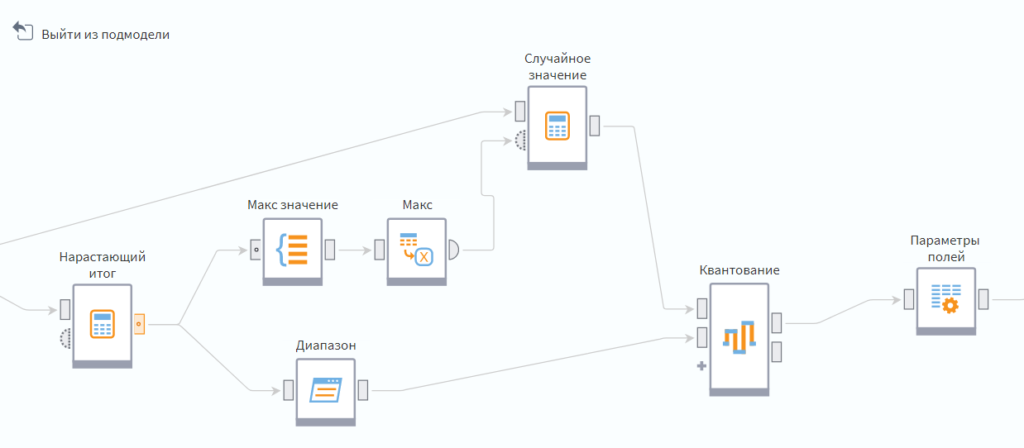
Как видите, опять используется нарастающий итог, чтобы создать шкалу значений вместо весов. Максимальное значение преобразуется в переменную и используется в калькуляторе, чтобы сопоставить каждому ID товара случайную величину в масштабах шкалы.

Узел ‘Диапазон’ на базе скользящего окна, позволяет превратить шкалу в диапазоны значений.

Теперь можно использовать модуль квантование, чтобы сопоставить случайную величину в таблице 1 с названием категории. Случайное значение квантуется, используя диапазон нарастающего итога, а в качестве метки выбирается название самой категории:
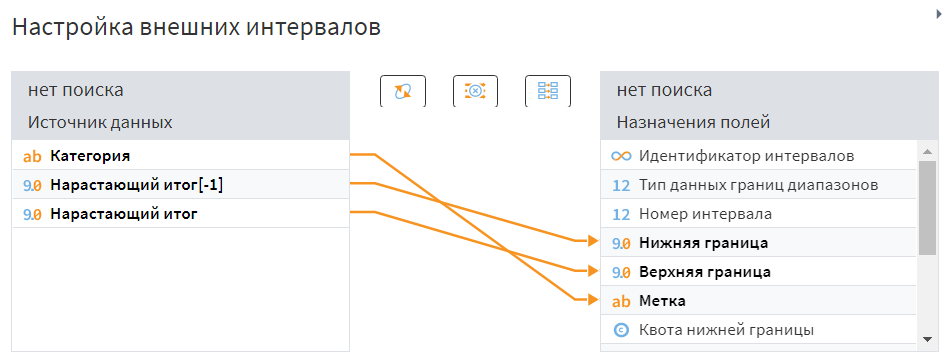
Используйте метод ‘внешние диапазоны’.
Т.к. квантование добавляет множество лишних полей, то для приведения к конечному результату, я еще использую модуль ‘Параметры полей’.

Здравствуйте! Можно вопрос, в моем задании сказано посчитать накопительный итог с помощью функции Data(“ИмяПоля”, RowNum()-1) и кэширования рассчитываемого поля. Подскажите, пожалуйста, каким образом это можно сделать??
Не подскажу, Вероника, как закончился у нас на курсах Логином, больше им не пользовался.